
Each integration created in SageData will trigger the creation of schema specific to that integration. The schema will be loaded to the destination you have already defined for your account. SageData will then save all the information replicated from the data source.
Terminology
In SageData, the term schema defines the location in your defined destination, where the integration data is loaded. Based on the destination infrastructure, the schema can differ.
Here are few examples:
- In case of traditional database as a destination, the information will be loaded to integration-specific schemas.
- In Amazon S3, the information will be loaded into integration-specific folders. The exact location in the S3 bucket is determined by the integration names and S§ Object Keys
- In Google BigQuery destinations, the information will be loaded to integration-specific datasets.
Integration schema names
Creating schema names
You will have to define a name for each integration you are creating. The same name will be used for the integration schema in your destination.

For example: Creating an integration using Facebook Page Insights with the integration name ‚Facebook Campaign 20220420’ would create a schema named sd__facebook_page_insights__facebook_campaign_20220420
Currently SageData does not support manual change of the integration schemas’ name. If you would need a different name than the one provided automatically, please contact SageData support and we will assist you by making the change for you.
Changing schema names
Once the integration has been created and saved, the integration schema name can’t be changed by the user. If you want to change the name, you will have to create new integration and replicate the data.
Re-using schema names
If you try to create an integration using the name of an existing one, you will see an error.

You are able to reuse schema names of deleted integrations. Please note that this may cause rejection of the data in your destination, as the deleting of integration won’t remove the integration’s schema and data, saved to your destination.
Schema composition
Each integration schema will contain two types of tables created by SageData:
- Integration tables
- SageData system tables
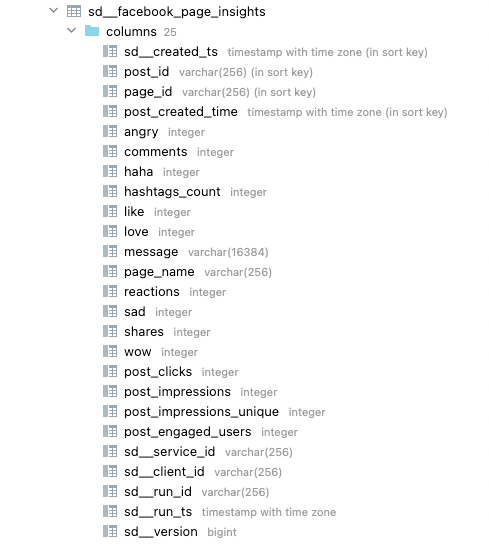
Integration tables
The tables created by SageDate for each integration depend on whether the integration supports data selection. If data selection is available, Sage Data will create only the tables/columns, that you selected for replication. Otherwise, all available tables and columns will be replicated.
SageData system tables
System tables are created in addition to your integration tables. For each integration, SageData will create a _sdc_rejected table, which serves as a log for data loading issues.
If you are using a Microsoft Azure Synapse Analytics or Google BigQuery (v2) destination, an additional table named _sdc_primary_keys will be created in the integration schema. This table includes the primary keys for the tables in the integration schema.
Integration table schemas
The integration tables consist of the replicated data from tables, which you selected to replicate.
A table won’t be removed from your destination by simply de-selecting the table for replication.
Data storage
The way SageData stores your data in the schemas depends on:
- the way the data is structured in the data source (example: nested structures)
- changes you make to the data source (example: adding/removing a column),
- SageData-specific data handling
- The way your destination handles data (example: nested data structures)
SageData system (_sdc) columns
You will notice that SageData will create a few columns prepended with _sdc in addition to the ones you have selected to be replicated. Don’t remove these columns, as SageData uses those columns in order to replicate the data properly.
For descriptions of the system columns used by SageData, refer to the System tables and columns guide.