
Last week SageData team deployed an upgrade that allows our clients to run integrated Development and Production Airflow instances with CI/CD. To expand further on the value of this upgrade and to explain how a Data team can use this feature to test their code prior to production deployment, we decided to post this blog.
So why Development and Production?
There are a lot of reasons why a well-structured and disciplined Data team may want to adopt the practices that have been the staple of the software development industry. More important of them all is to ensure that production ETL pipeline does not execute erroneous code.
Let’s assume that a normal size BI tam has about 5 to 10 people. At any point these individuals are working on various data related features and ensuring that this code works together smoothly is key to running a stable data pipeline. When the Data team is working directly on a singular ETL Instance, a feature that was deployed may be referencing a table that is being dropped by a feature being deployed today and in order to ensure that the new deployment does not break anything that was built in the past.
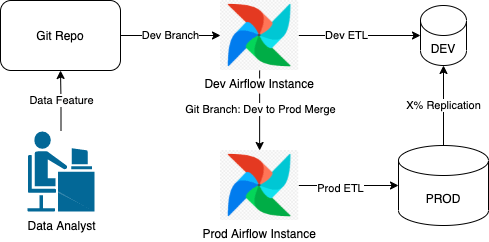
This is where Development instance comes in.
Ideally a Development instance will be pointing to the development Data Warehouse that will have identical DDL structure to production but can contain as little as 5% of data in order to simulate the production execution environment without the data load to facilitate quick testing.
So how does this work in practice?
Well, in plan terms it will look a something like this
- Data Analyst writes and test code in their local environment
- Once the code is pushed into Git and Merge Request / Pull Request is created, the new feature is merged automagically into the Dev Airflow instance
- If the development airflow instance executes successfully, the whole Dev branch can be merged into Prod branch.
If the development branch does not execute successfully, no harm is done to the production pipeline.
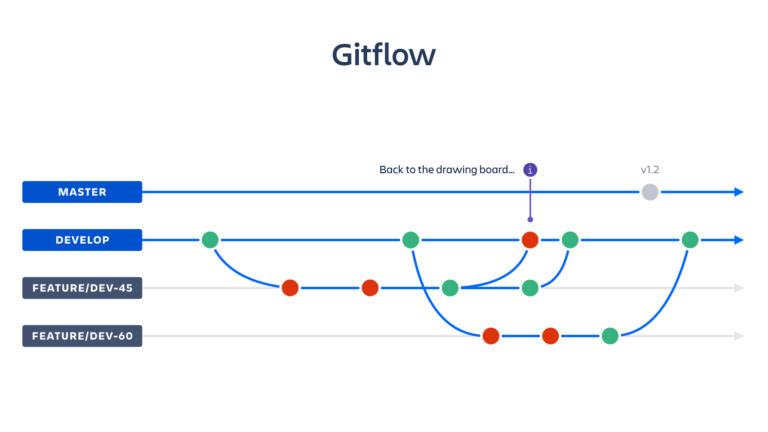
This can also be illustrated with a standard Gitflow
Merging data modeling code changes into development and automatically testing it may sound like a minor nuisance to the many already overloaded Data Teams. However, our practice shows that this disciplined approach saves a lot of time in the long run, because there is less effort invested in fixing mistakes and untangling code dependencies that are contradictory.
Would you like to see the value of this process on your data?
Reach out to our team for a quick introduction and a trial